Introduction to AI Engineering
I’ve been exploring AI Engineering recently—a field that sits right at the intersection of software engineering and data science. This post is the first in a series where I’ll share my notes and learnings as I dig deeper into what it takes to build production-ready AI systems.
What is AI Engineering?
AI Engineering is about making AI work in the real world. It bridges the gap between theoretical research and practical application. While data science focuses on model accuracy and discovery, AI engineering focuses on reliability, scalability, and maintainability.
It integrates principles from:
- Software Engineering: Code quality, testing, CI/CD.
- Data Science: Understanding models and data.
- MLOps: Automating the lifecycle of ML systems.
The Role of an AI Engineer
Unlike AI Researchers (who invent new algorithms) or ML Engineers (who train and optimize models), an AI Engineer focuses on integrating these models into products. They take a “good enough” model and build a robust system around it.
Core Concepts
AI Engineering distinguishes itself by emphasizing the entire lifecycle of an AI system, not just the training phase.
1. Productionizing Models
Turning a Jupyter notebook into a production service requires more than just exporting a file. It involves handling latency, throughput, error management, and ensuring the model can handle real-world traffic without crashing.
2. System Design for AI
This involves architectural choices:
- Batch vs. Real-time: Do we need immediate predictions or nightly processing?
- Cloud vs. Edge: Should the model run on a server or the user’s device?
- Infrastructure: Selecting the right GPUs, containers, and orchestration tools.
3. Data Management
Garbage in, garbage out. AI Engineers build robust pipelines to validate, version, and transform data. They ensure that the data feeding the model in production matches the quality of data used during training.
The AI Engineering Lifecycle
The lifecycle is a continuous loop, not a straight line.
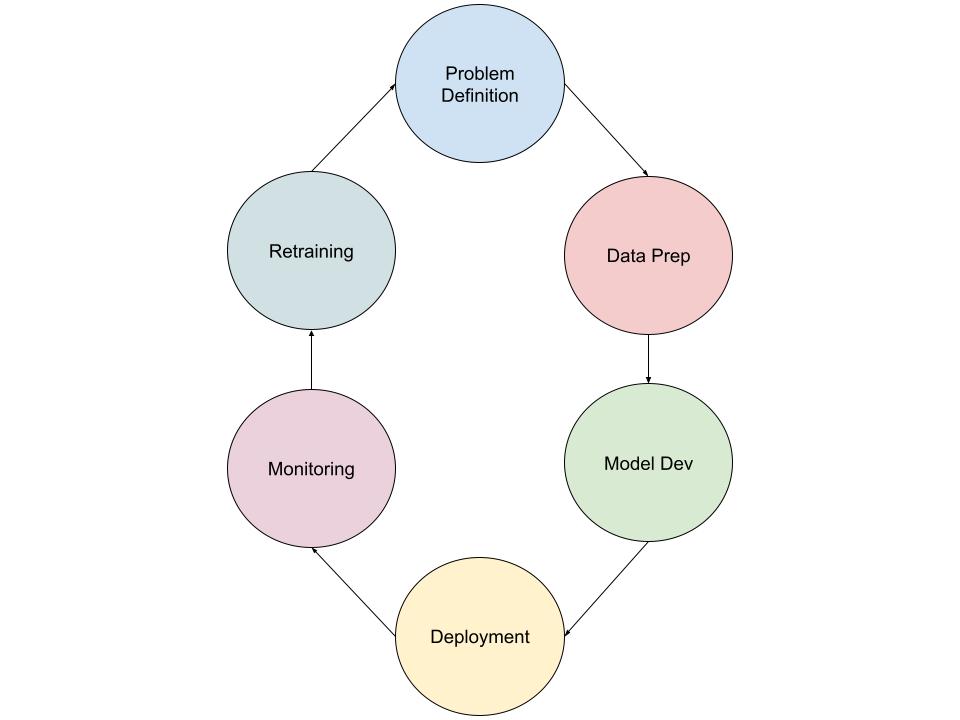
1. Problem & Data
Define the business goal. Is AI actually the right tool? If so, what data do we need, and do we have access to it?
2. Preparation & Engineering
Cleaning data and building feature pipelines. This step is critical; consistent feature engineering between training and inference prevents “training-serving skew.”
3. Development (The Handoff)
While researchers train the models, AI Engineers ensure the training environment is reproducible. They containerize training scripts so that any run yields the same result given the same data.
4. Deployment
This is where the rubber meets the road. Deployment strategies include:
- API Services: Wrapping models in FastAPI or Flask.
- Containerization: Dockerizing the service for consistency.
- Orchestration: Managing replicas with Kubernetes.
Here is a simple example of serving a model using Flask:
# simple_inference_api.py
from flask import Flask, request, jsonify
import joblib
app = Flask(__name__)
model = joblib.load("model.pkl")
@app.route('/predict', methods=['POST'])
def predict():
try:
data = request.json['features']
# Ensure input format matches model expectation
prediction = model.predict([data]).tolist()
return jsonify({'prediction': prediction, 'status': 'success'})
except Exception as e:
return jsonify({'error': str(e), 'status': 'error'}), 400
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
5. Monitoring & Maintenance
Deploying is just the beginning. Models “rot” over time as the world changes.
- Data Drift: Has the input data distribution changed? (e.g., user behavior shifts).
- Model Drift: Is the model’s accuracy dropping?
- System Health: Latency, error rates, and resource saturation.
6. Retraining
Monitoring triggers retraining. This closes the loop, allowing the system to adapt and improve continuously without manual intervention.